LADAL Webinar Series 2022
Martin Schweinberger

The LADAL Webinar Series 2022 consists of 6 webinars | online presentations from speakers with backgrounds in linguistics, data science, or computational humanities and it covers topics related to the computational handling of language data! All recordings of the webinar series are available on the LADAL YouTube channel.
Details about upcoming and past webinars that are part of the LADAL Webinar Series 2022 can be found below.

All events were announced on Twitter (@slcladal), via the UQ School of Languages and Cultures, and via our collaborators) - so please follow us if you like to catch up with the activities at LADAL. Below are links to recordings of past webinars on our YouTube channel.
Spread of Lexical Innovations (Jack Grieve)
Archives as Subject not Source (Cedric Courtois)
Analyzing Longitudinal Data (Dimitrios Vagenas)
Bayesian GLMMs with brms (Bodo Winter)
LADAL Webinar Details
Below you will find the details of the webinars including abstracts, bioblurbs of the speakers, and additional resources.Please note that we have only included confirmed webinars | online presentations at the moment - so more webinars and online presentations will be added once they are confirmed! Stay put and check this space if you want to find out more.
Past webinares
Spread of Lexical Innovations (Jack Grieve)
The Spread of Lexical Innovation is Constrained by Cultural
Patterns
This talk was recorded March 7, 2022, as part of the LADAL Webinar
Series 2022.
Recording link: https://youtu.be/sW70Y6XDiRA
Abstract
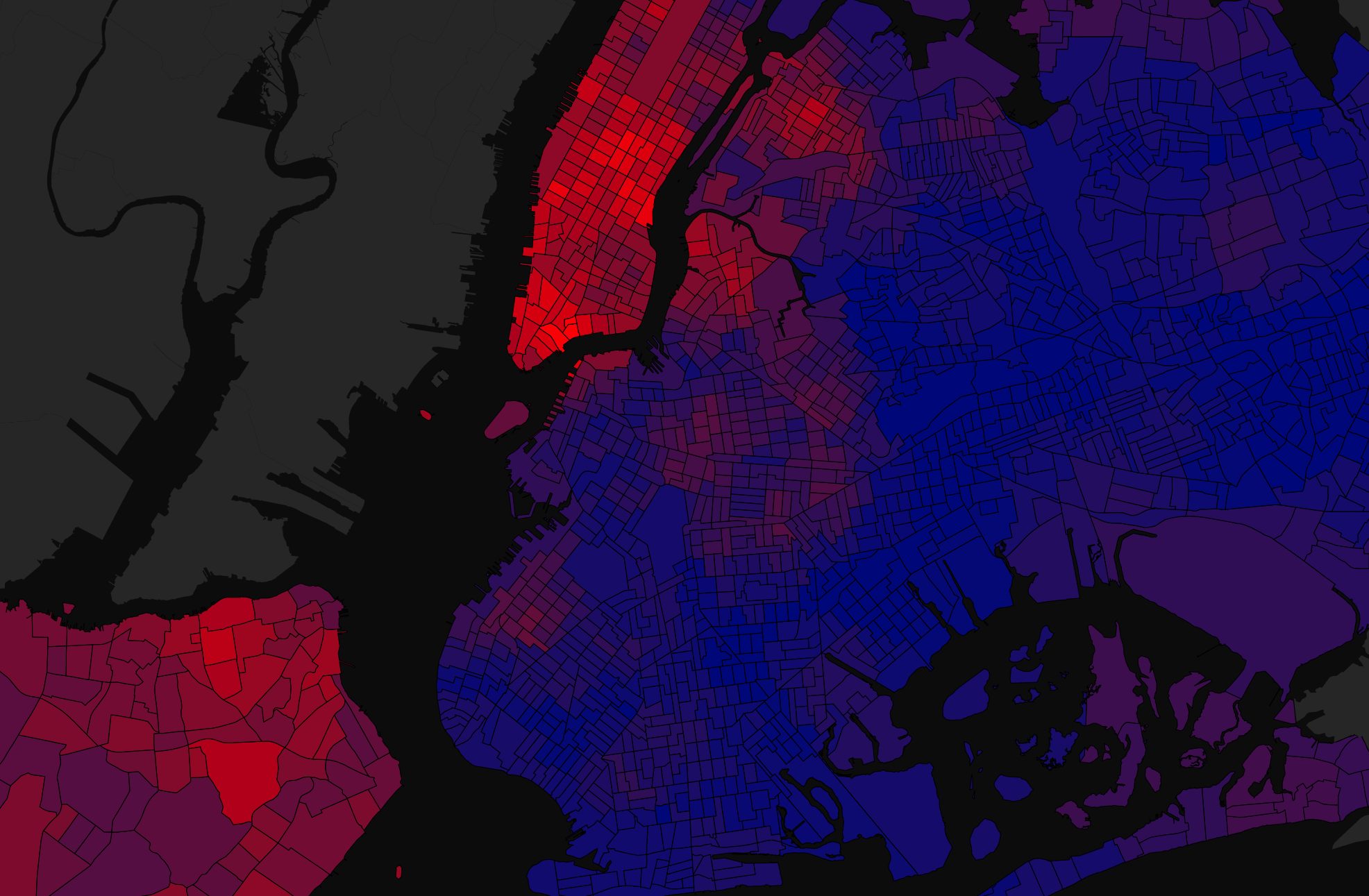
In this talk I discuss the results of three studies on the geographical
diffusion of lexical innovation, all of which are based on the analysis
of multibillion word corpora of Twitter data collected between 2013 and
2014. In this first study, I track the spread of new words across the
US. In the second study, I zoom in and look at how these same words
spread out across New York City. In the third study, I consider how
lexical items from Multicultural London English have diffused across the
UK. In all cases, I show that the spread of lexical innovation is not
only constrained by physical distance and population density, as
predicted by the Wave and Gravity Models, but by cultural patterns and
boundaries.

About Jack
Jack Grieve is Professor of Corpus Linguistics at the University of Birmingham and Turing Fellow at the Alan Turing Institute. His research involves analysing large corpora of natural language to understand language variation and change. He is especially interested in grammatical and lexical variation in the English language across time, space and communicative context, as well as developing methods for quantitative linguistic analysis. Jack also conducts research on authorship analysis and sometimes consult on casework as a forensic linguist. You can get in touch with Jack at j.grieve@bham.ac.uk or via his Twitter handle @JWGrieve.
Archives as Subject not Source (Cedric Courtois)
The Archive as Subject rather than Source: a Roadmap to
Constructing and Disseminating a Digital Archive

This talk was recorded May 9, 2022, as part of the LADAL Webinar
Series 2022.
Recording link: https://youtu.be/-dcwbKZuzDU
Abstract
Archives are valuable resources in historical media and communication
research. Unfortunately, many collections are hard to find and access,
and have not been properly digitised and described. In this paper we
argue that computational methods are instrumental in engaging with and
digitising archive materials, even though these methods introduce
problems of their own. More specifically, we articulate critical
thinking on the concept of ‘the archive’ with a discussion of the key
decisions and practical hurdles encountered in the construction and
digitisation of an archive. This is illustrated by a mid-sized project
based on records of communications between the Pentagon and CIA
Entertainment Liaison Offices (ELO) and audiovisual productions
companies around the world, which are key in revealing influence of the
US military on the entertainment industry. However, rather than
discussing every step in the project in minute detail, we maximise the
relevance for a broad readership by distilling a generic roadmap and key
recommendations that cover all stages of strategic decision-making in
archive construction and digitisation, as well as demonstrating the
required generic technical implementations.

About Cedric
Cedric Courtois is a senior lecturer in the School of Communication and Arts in the Faculty of Humanities and Social Sciences at the University of Queensland. He is both an audience researcher and a methodologist. His research interests include algorithmic impact in digital culture and data science applications in (digital) media and communication research (including text mining and image processing).
Analyzing Longitudinal Data (Dimitrios Vagenas)
Analyzing Longitudinal Data

This talk was recorded July 4, 2022, as part of the LADAL Webinar
Series 2022.
Recording link: https://youtu.be/oKZHRHqU0YY
Zoom link: https://uqz.zoom.us/j/86849442143
Abstract
The focus of the current seminar will be a (very) brief introduction
to longitudinal data and their analysis focusing on regression. To start
with we will look at longitudinal data and different designs for
collecting such data. We will then look at some empirical observations
and why they occur before turning our attention to simple linear
regression and why it is generally not appropriate to use it for the
analysis of such data. Understanding the above is very important but
also a neglected aspect of longitudinal data. We will then, very
briefly, introduce two methods for appropriately analysing such data:
(i) mixed models and (ii) Generalised Estimating Equations.

About Dimitrios
Dimitrios is a biostatistician and the head of the Research Methods Groups at the Queensland University of Technology. He is also the President of the QLD branch of the Statistical Society of Australia and a member of the Accreditation committee of the same society. He also holds the highest professional accreditation of the American Statistical Association and the Royal Statistical Society. He has also studied animal science, quantitative genetics, and digital biology. His main job is to help researchers do better research and he enjoys working in multidisciplinary teams.
The travels of Marco Polo (Andreas Niekler)
The travels of Marco Polo: Information extraction and
visualization of historic travel literature
This talk was recorded September 26, 2022, as part of the LADAL
Webinar Series 2022.
Recording link: https://youtu.be/oJFmw1Sy7iE
Abstract
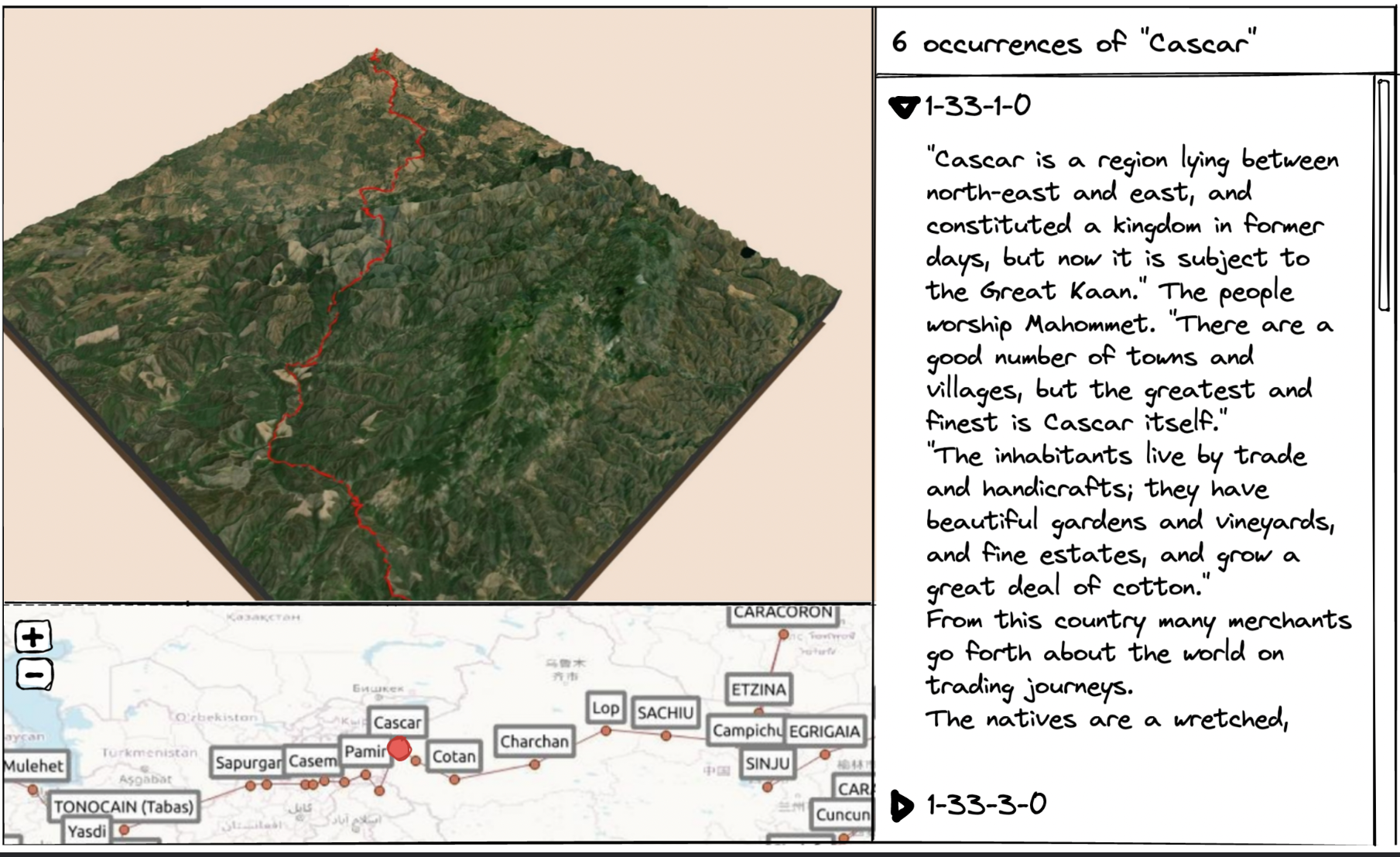
Marco Polo was born into a wealthy Venetian merchant family in 1254
and at the age of 17 he embarked on an epic journey to Asia, as one of
the first westerners to ever visit China. When he returned 24 years
later he recorded his extensive travels in a book – publishing possibly
the first travel guide ever – and introducing Europeans to Central Asia
and China.
In our talk we show our preliminary work on the analysis of travel
literature using Marco Polo’s travel diaries as an example. First, we
show the annotation and automatic extraction of important landmarks. On
the other hand, we propose an extraction procedure that can uncover
possible movements and route segments from the text. This is
complemented by a geo-visualization that does not only show a map, but
rather works with the spatial situation and terrain models, so that the
landscape context can provide complementary information for the text
itself. With this work we hope to contribute to a better understanding
of historical journeys.

About Andreas
Andreas Niekler is a research associate at the Institute of Computer Science at the University of Leipzig. He develops computer-based methods in the field of semantic properties in language and language-based AI. He develops computer-based algorithmic methods for computational social science and digital humanities research. Here he has contributed primarily text mining methods to political science, cultural studies, and communication research. Within several research projects he was also involved in the development of the interactive Leipzig Corpus Miner. An interactive and graphical tool for intuitive work with large text corpora and modern methods of text mining.
Bayesian GLMMs with brms (Bodo Winter)
Bayesian generalized linear mixed models with
brms
This talk was recorded November 7, 2022, as part of the LADAL Webinar
Series 2022.
Recording link: https://youtu.be/UwIgWD5pWzQ
Abstract
Linguistics is undergoing a rapid shift away from significance tests
towards approaches emphasizing parameter estimation, such as linear
mixed effects models. Alongside this shift, another revolution is
underway: away from using p-values as part of a “null ritual”
(Gigerenzer, 2004) towards Bayesian models. Both shifts can nicely be
dealt with the ‘brms’ package (Bürkner, 2017). After briefly reviewing
why we shouldn’t blindly follow the “null ritual” of significance
testing, I will demonstrate how easy it is to fit quite complex models
using this package. I will also talk about how mixed models are used in
different subfields of linguistics (Winter & Grice, 2021), and why
established practices such as dropping random slopes for non-converging
models are a further reason to go Bayesian. Finally, I will briefly
touch on issues relating to prior specification, especially the
importance of weakly informative priors to prevent overfitting.

About Bodo
Bodo Winter is a Senior Lecturer at the Department of Linguistics at the University of Birmingham, a UKRI Future Leaders Fellow, a Fellow of the Institute for Interdisciplinary Data Science and AI, and Editor-in-Chief at the journal Language and Cognition. Dr. Winter has received his PhD in Cognitive and Information Sciences from the University of California, Merced. His research focuses on multimodality, sound symbolism, gesture, and metaphor.
Found in Translation (Jörg Tiedemann)
Found in Translation - What can we learn from translations
about languages and human communication

This talk was recorded December 5, 2022, as part of the LADAL Webinar
Series 2022.
Recording link: https://youtu.be/feF987aX5s8
Abstract
The goal of language technology is to create computational models
that can understand and generate language in a way humans can do. One of
the strategies is to learn such communication abilities from real-world
data and in that way somewhat resemble humans and their capability of
picking up language skills through practical experience. However, the
crucial question is what kind of experience is needed and what kind of
tasks have to be practiced to build an understanding of human language
signals. We are currently running a project that studies the use of
translations that form natural semantic mirrors of original texts in
other languages as a means of providing information about the underlying
latent meaning that corresponds to the observable language string. The
big question is what kind of abstractions can be learned from this
cross-lingual signal and how much does that reflect our knowledge about
linguistic properties on various levels. Part of this question is how
much language diversity can be used to push abstraction levels even
further. In this talk I will present some of our results and try to
connect this kind of neural “black-box” NLP with questions in general
linguistics and cognition.

About Jörg
Jörg Tiedemann is professor of language technology at the Department of Digital Humanities at the University of Helsinki. He received his PhD in computational linguistics for work on bitext alignment and machine translation from Uppsala University before moving to the University of Groningen for 5 years of post-doctoral research on question answering and information extraction. His main research interests are connected with massively multilingual data sets and data-driven natural language processing and he currently runs an ERC-funded project on representation learning and natural language understanding.
Website: https://blogs.helsinki.fi/tiedeman/
Griffith Digital Humanities Webinar Series

Martin Schweinberger and Michael Haugh presented about ATAP and LADAL at the Griffith Digital Humanities Webinar Series on Friday May 20, 2022. For more information about this webinar series and the Griffith Centre for Social and Cultural Research see here.